Flutter Web, a Dart gRPC server and Firebase Authentication
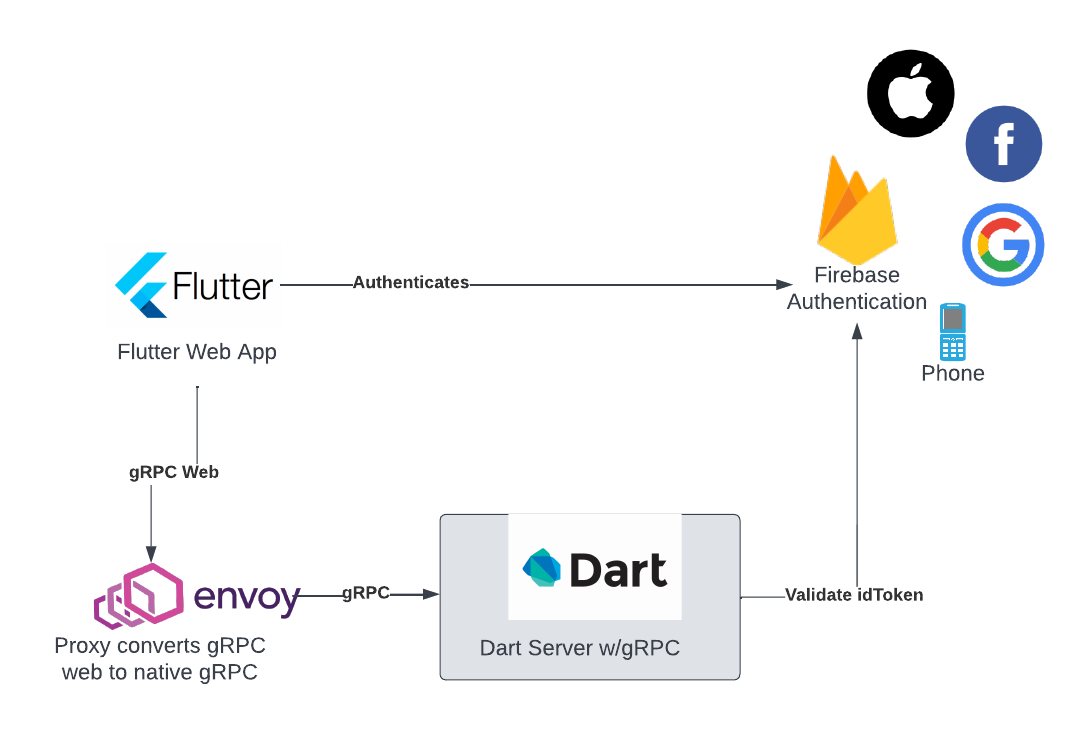
OK, not the sexiest title, but here is a quick overview of how you can create a flutter web application (or mobile for that matter, but more on that later), using Firebase authentication , talking to a pure Dart server using gRPC. The goal here is to: Create a SPA Flutter web application. Leverage Firebase authentication. It's inexpensive (essentially free for most users), and supports a wide variety of social login providers. Support a native Dart Server, using gRPC and protobufs. Proxy from gRPC web to gRPC "native" using envoy. Putting it together, it looks something like this: Why the choice of gRPC here, instead of json/REST? This comes down to personal preference, but I have always liked the contract first approach of gRPC of defining interfaces using protobufs. In theory, you can do this with OpenAPI - but I've yet to see a moderately complex interface where the generated API stubs look even remotely usable. gRPC does a good job of generating usable client a...